목차
인공지능: 머신러닝과 딥러닝의 차이
안녕하세요, 여러분! 오늘은 인공지능 분야에서 떠오르는 주요 기술인 머신러닝과 딥러닝의 차이에 대해 자세히 살펴보겠습니다. 이제 많이 들어보셨을 "머신러닝(ML)"과 "딥러닝(DL)" 용어는 서로 유사한 것 같지만, 사실은 그들 사이에 약간의 차이가 있습니다. 함께 이해해보도록 하겠습니다.

머신러닝과 딥러닝: 개념 이해
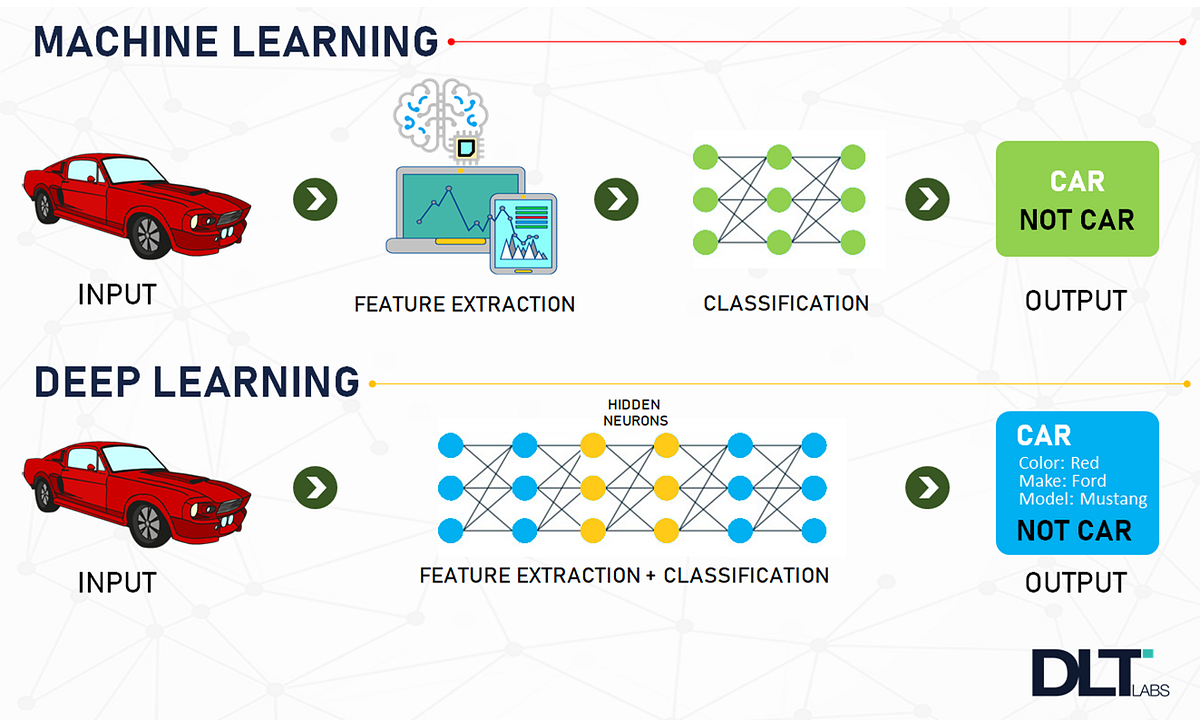
머신러닝은 컴퓨터 시스템이 데이터로부터 학습하고 패턴을 추출하여 결정을 내리는 기술입니다. 이는 주어진 데이터와 해당 데이터의 특성을 기반으로 모델을 훈련시켜 새로운 데이터에 대한 예측을 수행합니다. 머신러닝은 주로 수작업으로 프로그래밍하는 대신에 데이터를 활용하여 컴퓨터가 스스로 학습하도록 하는 방식을 강조합니다.
반면에 딥러닝은 머신러닝의 한 분야로, 인공신경망을 사용하여 데이터로부터 패턴을 학습하는 과정을 강조합니다. 딥러닝 모델은 여러 개의 층으로 구성되어 있으며, 각 층은 데이터의 특성을 점차적으로 추상화하여 높은 수준의 특징을 학습합니다. 이러한 다층 구조는 복잡한 데이터에서 뛰어난 성능을 발휘하며, 이미지 인식, 자연어 처리와 같은 작업에서 탁월한 결과를 보여줍니다.

머신러닝과 딥러닝: 차이와 활용 분야
머신러닝과 딥러닝의 주요 차이점은 주로 모델의 복잡성과 활용 분야에 있습니다. 머신러닝은 일반적으로 상대적으로 단순한 모델로 다양한 작업을 처리합니다. 예를 들어, 통계적 분석, 패턴 인식, 예측 분석 등이 있습니다. 그러나 복잡한 문제나 대규모 데이터셋을 다루는 데는 한계가 있습니다.
반면 딥러닝은 이러한 한계를 극복하고 복잡한 문제에 대한 해결책을 제시합니다. 이미지, 음성, 텍스트와 같이 비구조화된 데이터를 처리하며, 자연어 처리, 음성 인식, 이미지 분석과 같은 고급 작업을 수행하는 데 뛰어난 성능을 보입니다. 딥러닝은 모델의 복잡한 구조와 깊은 계층 구조를 통해 데이터의 다양한 특징을 추출하고 이해하는 능력을 지니고 있습니다.
머신러닝과 딥러닝의 한계와 전망
물론 머신러닝과 딥러닝 모두 장점 외에도 한계가 있습니다. 머신러닝은 데이터의 품질과 양에 따라 성능이 크게 좌우될 수 있습니다. 또한 복잡한 데이터나 다양한 특징을 잘 처리하지 못하는 경우도 있습니다. 딥러닝의 경우에도 모델의 학습에 많은 데이터와 연산 자원이 필요하며, 과적합 문제가 발생할 수 있습니다.
앞으로는 머신러닝과 딥러닝을 보완하고 협업하여 더 나은 결과를 얻는 방향으로 발전할 것으로 예상됩니다. 머신러닝은 소규모 데이터나 간단한 작업에 적합하며, 딥러닝은 대규모 데이터와 복잡한 작업에 적합하다는 각 분야의 특징을 활용하면서 발전할 것입니다.

다양한 딥러닝의 학습 방법들
안녕하세요, 여러분! 딥 러닝 모델은 다양한 방법으로 학습할 수 있는 다재다능한 기술입니다. 아래에서는 각 학습 방법의 주요 특징과 세부 사항을 알아보겠습니다. 이러한 학습 방법들은 딥 러닝의 다양한 응용 분야에서 활용됩니다.
지도 학습 (Supervised Learning)
지도 학습은 가장 일반적으로 사용되는 학습 방법 중 하나입니다. 이 방법은 입력 데이터와 그에 상응하는 레이블을 함께 사용하여 모델을 훈련시키는 것을 의미합니다. 모델은 주어진 입력 데이터와 레이블 간의 관계를 학습하여 새로운 입력 데이터에 대한 정확한 출력을 예측할 수 있습니다. 예를 들어, 이미지 분류나 언어 번역과 같은 작업에 널리 사용됩니다.
비지도 학습 (Unsupervised Learning)
비지도 학습은 입력 데이터에 대한 레이블이 없는 상태에서 모델을 훈련하는 방법입니다. 모델은 데이터의 내부 패턴이나 구조를 발견하려고 노력하며, 주로 데이터의 군집화(clustering)나 차원 축소(dimensionality reduction)와 같은 작업에 사용됩니다. 이 방법은 데이터의 숨겨진 특징을 발견하는 데 유용합니다.
준지도 학습 (Semi-Supervised Learning)
준지도 학습은 일부 데이터에만 레이블을 제공하고 나머지 데이터는 레이블이 없는 상태에서 모델을 훈련시키는 방법입니다. 이 방법은 레이블이 부족한 상황에서도 모델의 성능을 향상시키는 데 도움이 됩니다. 모델은 레이블이 있는 데이터와 없는 데이터의 관계를 학습하여 새로운 데이터에 대한 예측을 수행합니다.
자기 지도 학습 (Self-Supervised Learning)
자기 지도 학습은 모델이 자체적으로 레이블을 생성하여 훈련 데이터를 사용하는 방법입니다. 예를 들어, 텍스트 데이터에서 문맥을 예측하거나 이미지 데이터에서 일부 영역을 가려서 복원하는 작업을 수행하여 모델을 훈련할 수 있습니다. 이 방법은 레이블을 수작업으로 생성하지 않아도 되므로 비용 효율적입니다.
전이 학습 (Transfer Learning)
전이 학습은 한 작업에서 학습한 지식을 다른 작업으로 전달하여 모델의 성능을 향상시키는 방법입니다. 기본 모델을 미리 훈련시키고, 새로운 작업에 맞게 미세 조정하는 방식으로 사용됩니다. 이는 데이터가 부족한 상황에서도 효과적인 결과를 얻을 수 있는 방법입니다.
강화 학습 (Reinforcement Learning)
강화 학습은 모델이 환경과 상호작용하며 어떤 행동을 선택할지 결정하는 방법입니다. 모델은 어떤 행동을 선택하면 보상이나 패널티를 받으며, 이를 통해 더 나은 행동을 학습합니다. 주로 게임이나 자율 주행과 같은 영역에서 사용되며, 시행착오를 통해 학습하는 특징을 가지고 있습니다.
마무리하며
다양한 딥 러닝의 학습 방법들은 각각 특정한 상황이나 작업에 적합한 기능을 제공합니다. 이러한 방법들을 적절히 조합하거나 활용하여 모델을 훈련시키면 놀라운 성능과 다양한 응용 분야에서의 혁신을 이끌어낼 수 있습니다. 딥 러닝의 발전은 미래에 더욱 흥미로운 가능성을 제시할 것입니다. 감사합니다!
결론
인공지능 분야에서 머신러닝과 딥러닝은 각기 다른 역할과 활용 분야를 갖고 있습니다. 머신러닝은 간단한 작업과 데이터에서 효과적이며, 딥러닝은 복잡한 문제와 대규모 데이터셋을 다루는 데 뛰어난 성능을 발휘합니다. 앞으로 더 많은 발전이 있을 것으로 예상되며, 이를 통해 우리는 더 놀라운 인공지능 기술을 경험하게 될 것입니다.
이번 글이 여러분에게 도움이 되었기를 바랍니다. 감사합니다!
'IT 모바일 Gear Up' 카테고리의 다른 글
| 윈도우10 로그인 암호 없애기 윈10 비밀번호 해제 컴퓨터 암호 제거 윈도우 계정 암호 변경 (0) | 2023.08.17 |
|---|---|
| 캐리어 에어컨 에러코드 e3 ec 07 e1 46 03 p4 e6 e5 벽걸이 스탠드 시스템에어컨 자가진단 및 대처방법 캐리어 고객센터 전화번호 (0) | 2023.08.12 |
| vscode 검색 파일 찾기 단축키. 정규식 여러 단어 검색 치환 바꾸기 (0) | 2023.08.06 |
| 역대 로또당첨번호 전체모음 엑셀 다운로드 Excel AVERAGE, MEDIAN, COUNTIF, MOD 함수 활용 1등 통계 목록 (0) | 2023.08.05 |
| 삼성 에어컨 에러코드 e4, e1, c101 리모컨 자가진단. AS센터 출장 서비스 예약 전화번호 (0) | 2023.08.03 |




댓글